
Ολοκληρώνοντας στα δύο τελευταία μαθήματα την ενότητα του web scraping, είδαμε πώς μπορούμε να διαχειριστούμε με την Python περιεχόμενο και ιστοσελίδες του internet. Σήμερα θα δούμε ένα καλό παράδειγμα για να εξασκήσουμε τα όσα μάθαμε. Ένα πρόγραμμα με το οποίο μπορούμε να κατεβάζουμε περιεχόμενο από το internet για να το αποθηκεύσουμε μόνιμα στον υπολογιστή μας.
Προτάσεις συνεργασίας
Τα νέα άρθρα του PCsteps
Γίνε VIP μέλος στο PCSteps

Για να δείτε όλα τα μαθήματα Python από την αρχή τους, αλλά και τα επόμενα, αρκεί να κάνετε κλικ εδώ.
Πρόγραμμα: Κατέβασμα όλων των XKCD comics
Ιστοσελίδες που ανανεώνουν τακτικά το περιεχόμενό τους, όπως τα blog, έχουν τυπικά την εξής μορφή: μια κύρια σελίδα με την πιο πρόσφατη δημοσίευση και ένα κουμπί Previous για την μετάβαση στην αμέσως προηγούμενη δημοσίευση.
Εκείνη με τη σειρά της θα έχει επίσης κάποιο κουμπί Previous, κοκ, δημιουργώντας μια αλυσίδα από την πιο πρόσφατη μέχρι και την πρώτη δημοσίευση της ιστοσελίδας.

Αν θέλαμε ένα αντίγραφο του περιεχομένου του site για να μπορούμε να το διαβάσουμε στην τουαλέτα που δεν πιάνει το internet, θα έπρεπε να πλοηγηθούμε χειροκίνητα σε κάθε σελίδα και να την αποθηκεύσουμε. Πρόκειται για μια αρκετά βαρετή δουλειά, που μπορεί να αυτοματοποιηθεί με ένα πρόγραμμα.
Για όσους διαβάζουν comics στο διαδίκτυο, το XKCD είναι από τα σχετικά δημοφιλή, και η δομή του ταιριάζει με τη δομή που μόλις περιγράψαμε. Μας παρέχει, μάλιστα, την άδεια να κατεβάσουμε το περιεχόμενό του.
Θα χρειαζόμασταν κάμποσα μερόνυχτα για να κατεβάσουμε όλα τα κόμικς του, αλλά με λίγες γραμμές κώδικα αυτό θα γίνει σε μερικά λεπτά. Το πρόγραμμά μας πρέπει να:
- φορτώνει την κεντρική σελίδα του XKCD
- αποθηκεύει την εικόνα του κόμικς της παρούσας σελίδας
- ακολουθεί το link του κουμπιού Previous
- επαναλαμβάνει τις ενέργειες μέχρι να φτάσει στο πρώτο κόμικς

Αυτό σημαίνει ότι ο κώδικας θα πρέπει να κάνει τα ακόλουθα:
- Να ανακτά σελίδες με το module requests.
- Βρίσκει το URL της εικόνας του κόμικ της σελίδας με το beautiful soup.
- Να κατεβάζει και αποθηκεύει την εικόνα στον σκληρό δίσκο με τη συνάρτηση iter_content().
- Βρίσκει το URL του προηγούμενου κόμικ, από το link του κουμπιού Previous, και επαναλαμβάνει τη διαδικασία.
1ο Βήμα: Σχεδίαση προγράμματος
Ανοίγουμε ένα νέο αρχείο στον editor και το αποθηκεύουμε με κατάληξη .py (πχ XKCD.py). Στη συνέχεια, επισκεπτόμαστε τη σελίδα του XKCD. Αν ανοίξουμε τα εργαλεία προγραμματιστή του browser μας, κάνοντας επισκόπηση τα αντίστοιχα στοιχεία, θα διαπιστώσουμε τα εξής:
- Το URL του αρχείου της εικόνας του κόμικ δίνεται από το attribute href ενός στοιχείου <img>.
- Tο κουμπί “Prev” της σελίδας έχει ένα attribute rel με την τιμή prev.
- Στο πρώτο κόμικ, που δεν έχει άλλο προηγούμενό του, το κουμπί Prev θα μας οδηγήσει στη σελίδα https://xkcd.com/#. Δηλαδή προσθέτει ένα hashtag στο URL, ως ένδειξη μη ύπαρξης προηγούμενων σελίδων.
Με βάση τις παρατηρήσεις αυτές, γράφουμε τα παρακάτω:
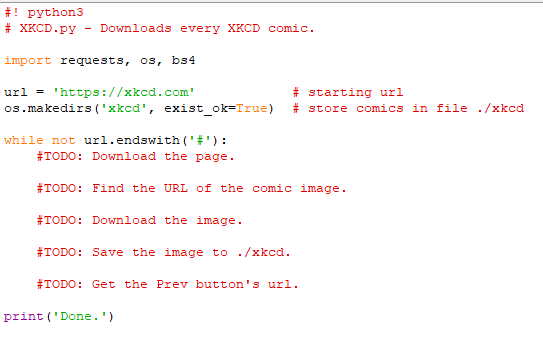
Θα έχουμε μια μεταβλητή url, η οποία αρχικοποιείται με τη διεύθυνση της σελίδας σε string, ‘https://xkcd.com'. Η τιμή της μεταβλητής θα ανανεώνεται κάθε φορά (σε έναν βρόχο for) με το URL που περιέχεται στο κουμπί Prev της τρέχουσας σελίδας.
Σε κάθε βήμα του βρόχου, θα κατεβάζουμε το κόμικς που έχει η url. Η εκτέλεση του βρόχου σταματάει μόλις η url λήγει στο σύμβολο #.
Κατεβάζουμε τα αρχεία των εικόνων σε έναν φάκελο στον τρέχοντα φάκελο εργασίας, τον xkcd. Η κλήση της os.makedirs() διασφαλίζει ότι αυτός ο φάκελος υφίσταται. Με την έκφραση exist_ok=True αποτρέπουμε την εμφάνιση εξαίρεσης, αν ο φάκελος όντως υπάρχει.
2ο Βήμα: Κατέβασμα σελίδας
Το επόμενο βήμα είναι να υλοποιήσουμε τον κώδικα που κατεβάζει την ιστοσελίδα. Συνεχίζουμε όπως παρακάτω:
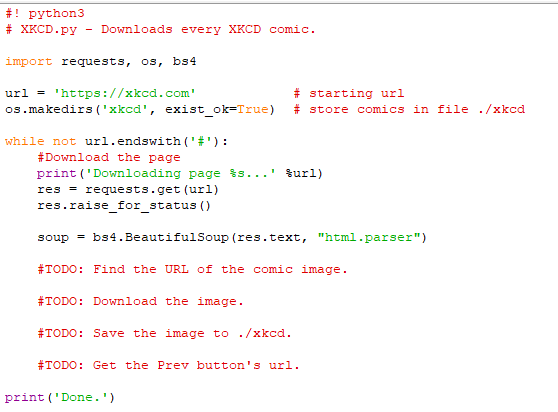
Αρχικά, κάνουμε μια εκτύπωση της url, για να γνωρίζει ο χρήστης ποιο URL είναι το επόμενο που θα κατεβάσουμε. Με τη συνάρτηση request.get() του module requests κατεβάζουμε τη σελίδα.
Αμέσως μετά καλούμε τη μέθοδο raise_for_status() του αντικειμένου Response, για να προκαλέσουμε εξαίρεση και τερματισμό του προγράμματος, αν κάτι δεν πήγε καλά με το download.
Αν όλα κυλήσουν ομαλά, δημιουργούμε ένα αντικείμενο beautiful soup από το κείμενο της κατεβασμένης σελίδας.
3ο Βήμα: Εύρεση και κατέβασμα εικόνας κόμικς
Προσθέτουμε τον ακόλουθο κώδικα:

Από τον έλεγχο (inspection) της αρχικής σελίδας του XKCD με τα εργαλεία προγραμματιστή, γνωρίζουμε ότι το στοιχείο <img> για την εικόνα του κόμικ βρίσκεται εντός ενός στοιχείου <div> με id attribute το comic.
Επομένως, ο selector ‘#comic img' θα μας φέρει το σωστό στοιχείο <img> από το αντικείμενο beautiful soup.
Είναι πιθανό κάποιες σελίδες του XKCD να έχουν κάποιο άλλο περιεχόμενο, πέραν από ένα απλό αρχείο εικόνας. Δεν μας πειράζει αυτό· μπορούμε απλά να τις προσπεράσουμε.
Αν ο selector δεν βρει κανένα στοιχείο, η soup.select(”#comic img) θα επιστρέψει μια κενή λίστα. Στην περίπτωση αυτή, το πρόγραμμα μπορεί να τυπώσει ένα τυπικό μήνυμα error και να συνεχίσει χωρίς να κατεβάσει την εικόνα.
4ο Βήμα: Αποθήκευση εικόνας και εύρεση προηγούμενου κόμικ
Μένει να γράψουμε τον κώδικα που αποθηκεύει την εικόνα και προχωρά, αφού βρει το αμέσως προηγούμενο κόμικ:
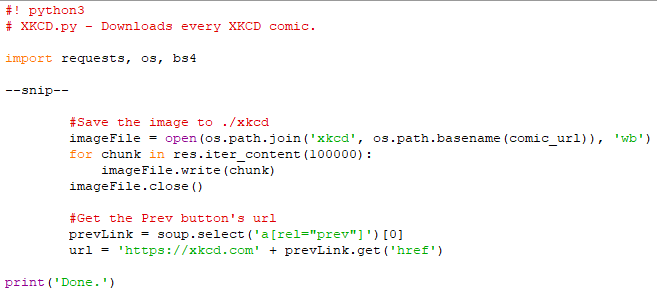
Στο σημείο αυτό, το αρχείο εικόνας για το κόμικ αποθηκεύεται στη μεταβλητή res. Θα πρέπει να γράψουμε τα δεδομένα της εικόνας σε ένα αρχείο του σκληρού μας δίσκου.
Χρειαζόμαστε όμως κι ένα όνομα για το τοπικό αρχείο εικόνας, για να το περάσουμε στην open(). Η comic_url θα έχει μια τιμή σαν κι αυτήν:
'http://imgs.xkcd.com/comics/heartbleed_explanation.png'
Η τιμή αυτή θυμίζει αρκετά ένα μονοπάτι αρχείου. Δοκιμάζοντας να καλέσουμε την os.path.basename() στην comic_url, ανακαλύπτουμε ότι όντως επιστρέφει το τελευταίο κομμάτι του URL, ‘heartbleed_explanation.png'.
Μπορούμε, προαιρετικά, να χρησιμοποιήσουμε το string αυτό ως όνομα για την εικόνα που αποθηκεύουμε στον σκληρό δίσκο. Αρκεί να το συνενώσουμε, με ένα join, με το όνομα του φακέλου xkcd, με τη βοήθεια της os.path.join(). Μένει να καλέσουμε την open() για να ανοίξουμε ένα νέο αρχείο σε κατάσταση δυαδικής εγγραφής (‘wb').
Υπενθυμίζουμε ότι για να αποθηκεύσουμε αρχεία που κατεβάσαμε με το requests, πρέπει να χρησιμοποιήσουμε βρόχο πάνω στην τιμή που επιστρέφει η μέθοδος iter_content(). Ο κώδικας στον for εγγράφει κομμάτια των δεδομένων της εικόνας, το πολύ 100.000 byte το καθένα, και κατόπιν κλείνει το αρχείο. Πλέον η εικόνα είναι αποθηκευμένη στο σύστημά μας.
Τέλος, ο selector ‘a[rel=”prev”]' αναγνωρίζει το στοιχείο <a> του attribute rel, που έχει τεθεί στην τιμή prev. Μπορούμε με το href attribute αυτού του στοιχείου <a>, να πάρουμε το URL του προηγούμενου κόμικ, και να το αποθηκεύσουμε στη url. Ο βρόχος while ξεκινάει την όλη διαδικασία κατεβάσματος για το κόμικ αυτό ξανά.
Το πρόγραμμα ολοκληρωμένο είναι κάπως έτσι:

Εκτέλεση προγράμματος
Εκτελώντας το πρόγραμμα, θα δούμε ένα κατεβατό μηνυμάτων για κάθε σελίδα και κόμικ που κατεβάζουμε.
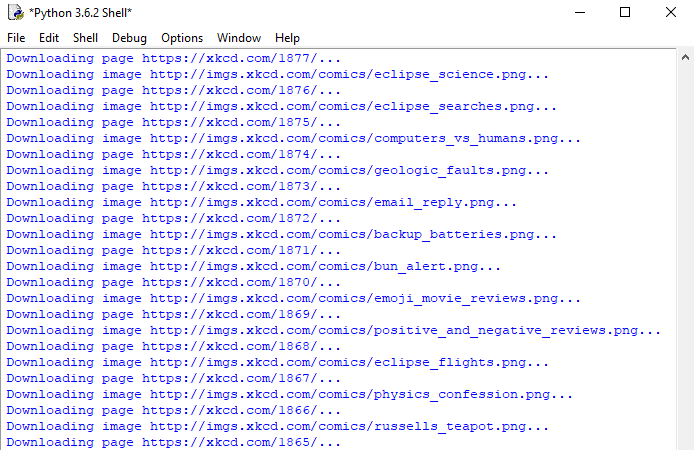
Περιμένοντας κάποια λεπτά (είναι πολλές οι σελίδες), μπορούμε να πάμε στον τρέχοντα φάκελο εργασίας μας, όπου έχει δημιουργηθεί ένας νέος φάκελος, ο xkcd.
Στα περιεχόμενά του θα βρούμε όλα τα κόμικς -ή τουλάχιστον όσα ταίριαζαν στο σύνηθες μοτίβο των σελίδων- σε εικόνες.

Στο επόμενο μάθημα για τον προγραμματισμό Python
Θα δούμε πώς μπορούμε να διαχειριστούμε τον χρόνο, για να προγραμματίσουμε εργασίες και να εκκινήσουμε προγράμματα με αυτόματο τρόπο.
Σας άρεσε το σημερινό μάθημα για τον προγραμματισμό Python?
Το πρόγραμμα που είδαμε σήμερα αποτελεί ένα καλό παράδειγμα κώδικα που ακολουθεί αυτόματα link για να κάνει ανάκτηση μεγάλης ποσότητας δεδομένων από το internet. Η αλήθεια είναι ότι σήμερα ασχοληθήκαμε περισσότερο με HTML, παρά με Python. Για οποιοδήποτε πρόβλημα ή απορία σας, γράψτε μας στα σχόλια.
Για να δείτε όλα τα μαθήματα Python από την αρχή τους, αλλά και τα επόμενα, αρκεί να κάνετε κλικ εδώ.




