
Στις σπάνιες στιγμές που βρισκόμαστε χωρίς Wi-Fi, διαπιστώνουμε πόσο η ενασχόλησή μας με τον υπολογιστή έχει να κάνει με το διαδίκτυο. Facebook, mail, PCsteps, έχουν γίνει για πολλούς αυτόματες ενέργειες με το που κάτσουν μπροστά στο PC. Θα ήταν, λοιπόν, αρκετά χρήσιμο, να μπορούμε να είμαστε online με την Python, και να αλληλεπιδράσουμε με το ίντερνετ μέσω των προγραμμάτων μας.
Προτάσεις συνεργασίας
Τα νέα άρθρα του PCsteps
Γίνε VIP μέλος στο PCSteps

Για να δείτε όλα τα μαθήματα Python από την αρχή τους, αλλά και τα επόμενα, αρκεί να κάνετε κλικ εδώ.
Web scraping
Παραδόξως, δικτυακό “ξύσιμο” δεν είναι το παίξιμο πασιέντζας online εν ώρα εργασίας. Ο όρος έχει να κάνει με τη χρήση κώδικα για το κατέβασμα και την επεξεργασία δεδομένων από το διαδίκτυο. Για παράδειγμα, η Google τρέχει πολλά προγράμματα web scraping για να κατατάσσει ιστοσελίδες για τη μηχανή αναζήτησής της.
Υπάρχουν αρκετά module της Python που μας βοηθούν στην ανάκτηση πληροφοριών από σελίδες του ίντερνετ:
- Webbrowser: Για άνοιγμα του browser σε μια συγκεκριμένη ιστοσελίδα.
- Requests: Για κατέβασμα αρχείων και σελίδων από το διαδίκτυο.
- Selenium: Για εκκίνηση και διαχείριση του browser. Με το selenium μπορούμε να συμπληρώσουμε πεδία και να υποκαταστήσουμε κλικ του ποντικού μας στον browser.
- Beautiful soup: Για διαχείριση HTML, του κώδικα στον οποίον είναι γραμμένες οι ιστοσελίδες.
Ας δούμε τι δυνατότητες μας παρέχει καθένα από αυτά.
Webbrowser
Πάμε να χρησιμοποιήσουμε πρώτα-πρώτα το webbrowser, το πιο απλό από τα προαναφερθέντα module.
Με τη συνάρτηση open() του webbrowser, ο browser θα ανοίξει και θα μεταβεί στο URL που περάσαμε στη συνάρτηση ως όρισμα. Γράφουμε τα παρακάτω στον IDLE:
>>> import webbrowser
>>> webbrowser.open('https://www.pcsteps.com/')
Μόλις τρέξουμε τις εντολές, ο browser μας θα ανοίξει μια νέα καρτέλα στη σελίδα του URL: το PCsteps.com.
Το κακό είναι ότι αυτό είναι όλο κι όλο που μας προσφέρει το webbrowser module. Αν και μπορεί να βρει εφαρμογή σε απλές εργασίες μας, δεν προσφέρεται για κάτι πιο πολύπλοκο.
Requests
Το module requests, που μας επιτρέπει να κατεβάζουμε εύκολα αρχεία από το ίντερνετ, δεν περιλαμβάνεται στην αρχική εγκατάσταση της Python. Επομένως, θα πρέπει να το κατεβάσουμε με τη διαδικασία που περιγράψαμε παλαιότερα.
Αφού ολοκληρώσουμε με τα προκαταρκτικά, ελέγχουμε στον IDLE αν εγκαταστάθηκε σωστά το module:
>>> import requests
Αν δεν εμφανίστηκε κάποιο μήνυμα error, το module εγκαταστάθηκε επιτυχώς.
Κατέβασμα περιεχομένου σελίδας
Για να κατεβάσουμε το περιεχόμενο μιας ιστοσελίδας από το ίντερνετ, θα χρησιμοποιήσουμε την συνάρτηση get. Η requests.get() παίρνει ως string το URL της σελίδας που θέλουμε να κατεβάσουμε.
Καλώντας την type() πάνω στη requests.get(), βλέπουμε ότι μας επιστρέφει ένα αντικείμενο “Response”, που περιέχει την απόκριση που έδωσε ο server στο αίτημά μας.
Ας γράψουμε τα ακόλουθα στον IDLE, έχοντας βεβαιωθεί ότι έχουμε σύνδεση στο διαδίκτυο:
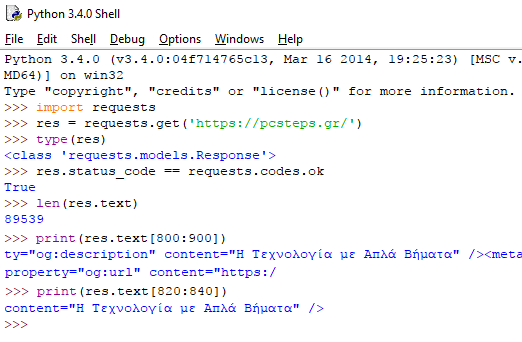
Το link μας οδηγεί στην κεντρική σελίδα του PCsteps. Έχουμε τη δυνατότητα να διακρίνουμε αν το αίτημά μας για τη σελίδα αυτή πέτυχε, ελέγχοντας τον κωδικό κατάστασης (status_code) του αντικειμένου Response. Αν είναι ίσο με την τιμή του requests.codes.ok, τότε δεν υπήρξε κάποιο πρόβλημα.
Εφόσον όλα πήγαν καλά, η ληφθείσα σελίδα αποθηκεύεται ως string στη μεταβλητή text του αντικειμένου. Στην text περιέχεται ένα τεράστιο string με ολόκληρη τη σελίδα. Βλέπουμε το μήκος του με τη len(res.text), ενώ μπορούμε με ένα print() να τυπώσουμε οποιοδήποτε κομμάτι του.
Είναι εμφανές από τις εκτυπώσεις στο παράδειγμά μας, ότι θα βρούμε χρησιμότητα για το module αυτό κυρίως σε σελίδες που περιέχουν απλό κείμενο. Σε διαφορετική περίπτωση, αποθηκεύουμε ουσιαστικά σε string ολόκληρο τον κώδικα της σελίδας.
Για παράδειγμα, αυτό είναι το περιεχόμενο που λαμβάνει η get() από μια άλλη ιστοσελίδα, που περιέχει απλό κείμενο:

Αποθήκευση σελίδας σε αρχείο
Στη συνέχεια, μπορούμε να αποθηκεύσουμε ό,τι κατεβάσαμε σε ένα αρχείο στον δίσκο μας, με τη συνάρτηση open() και τη μέθοδο write(), τις οποίες έχουμε δει σε προηγούμενο μάθημα. Υπάρχουν, όμως, κάποιες μικρές διαφορές.
Αρχικά, πρέπει να ανοίξουμε το αρχείο σε κατάσταση δυαδικής εγγραφής (write binary), περνώντας ως δεύτερο όρισμα στην open() το ‘wb' (και όχι σκέτο ‘w'). Ακόμα και αν όλη η σελίδα είναι γραμμένη σαν απλό αρχείο κειμένου, θα χρειαστεί να κάνουμε εγγραφή ως δυαδικά δεδομένα για να διατηρηθεί η κωδικοποίηση unicode στο κείμενο.
Για να γράψουμε τη σελίδα σε ένα αρχείο, θα χρειαστούμε έναν βρόχο for μαζί με τη μέθοδο iter_content() του αντικειμένου Response:
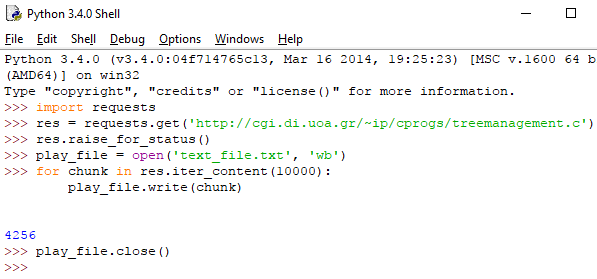
Η μέθοδος iter_content() επιστρέφει κομμάτια περιεχομένου σε κάθε επανάληψή (iteration) της. Ο τύπος δεδομένων κάθε κομματιού είναι bytes, και μπορούμε να καθορίσουμε το μέγεθός του με το αντίστοιχο νούμερο μες στην παρένθεση (σε byte).
Πλέον, το αρχείο text_file.txt υπάρχει στον τρέχοντα φάκελο εργασίας μας. Η μέθοδος write() επιστρέφει τον αριθμό των byte που έχουν εγγραφεί στο αρχείο.
Κάνοντας μια επισκόπηση της διαδικασίας, διακρίνουμε τα εξής βήματα:
- Με τη Requests.get() κατεβάζουμε το αρχείο.
- Κλήση της open() με ‘wb' για τη δημιουργία νέου αρχείου.
- Βρόχος με τη μέθοδο iter_content() του Response αντικείμενου.
- Εγγραφή του περιεχομένου στο αρχείο με κλήση τη write() σε κάθε επανάληψη.
- Κλήση της close() για να κλείσουμε το αρχείο.
Selenium
Το module selenium μας δίνει τη δυνατότητα να ελέγχουμε απευθείας τον browser, μέσω της Python. Με τη βοήθειά του μπορούμε να συμπληρώσουμε φόρμες εισόδου, να κάνουμε κλικ του ποντικιού σε κουμπιά, και γενικότερα να προσομοιώσουμε την ανθρώπινη συμπεριφορά σε μια ιστοσελίδα.
Στα αρνητικά του συγκαταλέγεται το γεγονός ότι είναι κάπως πιο αργό, κάτι που οφείλεται στο ότι ο browser πρέπει να εκτελείται κατά το τρέξιμο των εντολών.
Αν και στις επόμενες ενότητες γίνεται χρήση κάποιων στοιχείων HTML, δεν απαιτείται κάποια ειδική γνώση για να κατανοήσουμε τα παραδείγματα. Θα δούμε αναλυτικά ό,τι χρειάζεται να γνωρίζουμε για την HTML στο επόμενο μάθημα.
Έλεγχος browser
Στα παραδείγματά μας θα χρειαστούμε τον Firefox της Mozilla. Αν δεν τον έχετε, θα πρέπει να τον εγκαταστήσετε πριν συνεχίσουμε.
Η προετοιμασία για να χρησιμοποιήσουμε το selenium (τόσο για Chrome όσο και για Firefox) είναι λίγο πιο μπελαλίδικη από ό,τι έχουμε συνηθίσει. Αρχικά, και αυτό το module δεν έρχεται προεγκατεστημένο με την Python. Θα το κατεβάσουμε στο σύστημά μας με το εργαλείο pip από τη γραμμή εντολών.
Αφού ολοκληρωθεί η εγκατάστασή του, θα πρέπει να βρούμε και να κατεβάσουμε τους κατάλληλους drivers, στην περίπτωσή μας για τον Firefox (geckodriver).
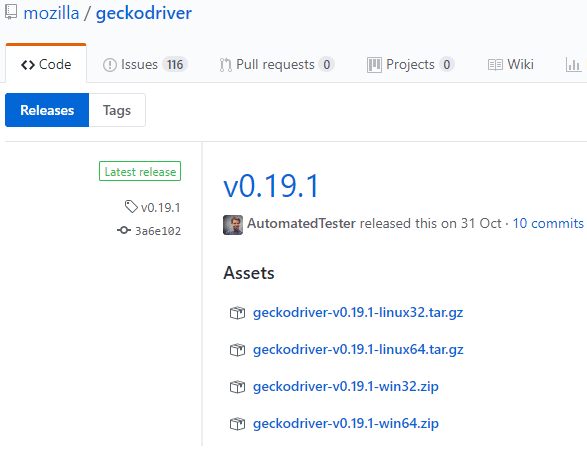
Εφόσον δουλεύουμε σε Windows, θα επιλέξουμε το αντίστοιχο (32- ή 64-bit) αρχείο zip. Εντός του αρχείου zip θα βρούμε ένα εκτελέσιμο αρχείο (exe), το οποίο αρκεί να εξάγουμε στον φάκελο εγκατάστασης της Python.
Έπειτα, αντί του τυπικού “import selenium”, θα πρέπει να τρέξουμε την εντολή:
from selenium import webdriver
Αν όλα πήγαν καλά, δεν θα πάρουμε κάποιο error. Αμέσως μετά, μπορούμε να ανοίξουμε τον Firefox. Εισάγουμε τις εξής εντολές στον IDLE:
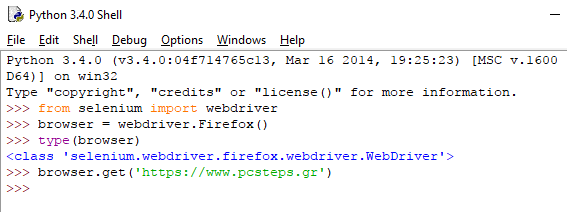
Με την εισαγωγή της δεύτερης εντολής, που καλεί τον Firefox, θα δούμε μια κονσόλα (το geckodriver.exe) και τον browser να ανοίγουν. Βλέπουμε με την type() ότι τα δεδομένα που περιέχει η μεταβλητή browser είναι τύπου “webdriver”.
Τέλος, με την browser.get() θα ανοίξει το URL που περάσαμε ως όρισμα, στον Firefox:

Εύρεση στοιχειών ιστοσελίδας
Τα αντικείμενα webdriver έχουν αρκετές μεθόδους για την εύρεση στοιχείων σε μια σελίδα. Αυτές χωρίζονται σε δυο κατηγορίες: τις find_element_* και τις find_elements_*.
Στην πρώτη κατηγορία επιστρέφεται ένα μόνο αντικείμενο web element της σελίδας, το πρώτο δηλαδή στοιχείο που ταιριάζει με την αναζήτησή μας. Η δεύτερη θα μας δώσει μια λίστα με όλα τα στοιχεία.
Για παράδειγμα, μπορούμε να γράψουμε το ακόλουθο πρόγραμμα στον editor μας:
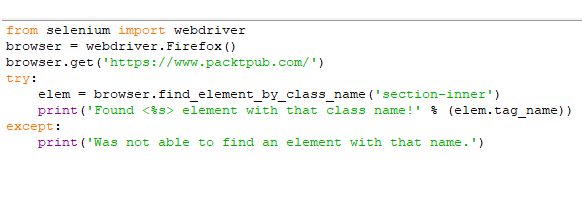
Το πρόγραμμα αυτό μας δίνει την παρακάτω εκτύπωση:

Εκείνο που κάναμε με το πρόγραμμα ήταν να αναζητήσουμε στη σελίδα packtpub (σελίδα με e-book) ένα στοιχείο με όνομα κλάσης (class name) ‘section-inner'.
Σε περίπτωση που το βρούμε, εκτυπώνουμε το όνομα ετικέτας (tag name), που στο παράδειγμά μας είναι το <div>.
Κλικ στην ιστοσελίδα
Τα αντικείμενα web element έχουν μια μέθοδο click() για την προσομοίωση κλικ ποντικιού στο συγκεκριμένο αντικείμενο. Μπορούμε να αξιοποιήσουμε την click() για να ακολουθήσουμε ένα link, να επιλέξουμε ένα κουμπί, ή γενικότερα να προκαλέσουμε οποιαδήποτε ενέργεια μπορεί να προέλθει από ένα κλικ.
Ας δούμε ένα παράδειγμα στον IDLE:
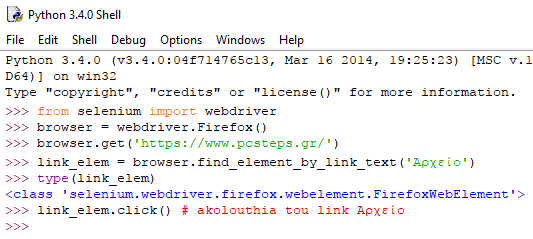
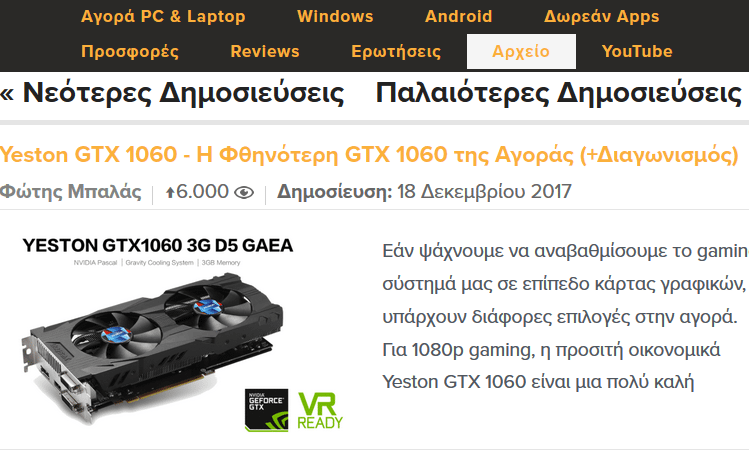
Με αυτές τις γραμμές κώδικα παίρνουμε το web element για το στοιχείο με το κείμενο ‘Αρχείο', και πατάμε κλικ για να μεταφερθούμε στην αντίστοιχη σελίδα. Βλέπουμε ότι όντως μεταφερόμαστε στη σελίδα Αρχείο του PCsteps.
Συμπλήρωση φόρμας
Η προσομοίωση πληκτρολόγησης σε πεδία κειμένου μιας ιστοσελίδας προϋποθέτει αρχικά να εντοπίσουμε τα στοιχεία <input> ή <textarea> για το εκάστοτε πεδίο. Στη συνέχεια, κάνουμε κλήση της μεθόδου send_keys(). Ως ορίσματα τοποθετούμε κάθε φορά τα διαπιστευτήριά μας, ή όποιο string κειμένου θέλουμε.
Ας δούμε ένα παράδειγμα, γράφοντας στον IDLE τις ακόλουθες εντολές:
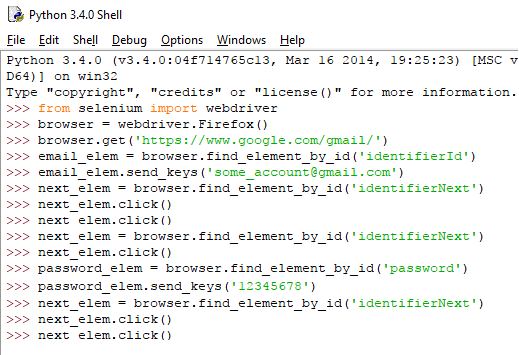
Όπως είδαμε και προηγουμένως, με τις πρώτες δύο εντολές (μετά την εισαγωγή του module) γίνεται η εκκίνηση του Firefox και, αμέσως μετά, το άνοιγμα της σελίδας εισόδου του Gmail.
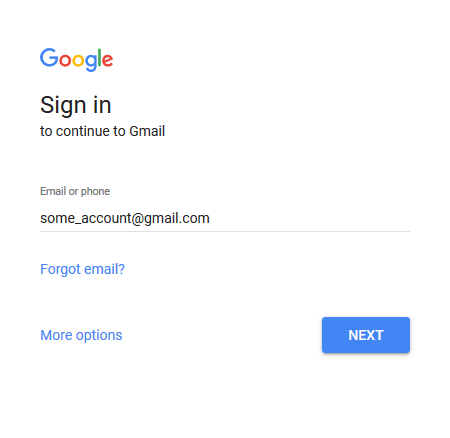
Κατόπιν, αναθέτουμε στη μεταβλητή email_elem το στοιχείο που αφορά το πεδίο όπου θα εισάγουμε τη διεύθυνση mail μας. Το στοιχείο αυτό στην προκειμένη περίπτωση ονομάζεται identifierId.
Να σημειωθεί ότι, όπως για κάθε τέτοιο στοιχείο μιας σελίδας, θα πρέπει να βρούμε από μόνοι μας την ονομασία του, προκειμένου να το χρησιμοποιήσουμε στις μεθόδους και τις συναρτήσεις μας.
Έτσι, με τη χρήση της send_keys() πάνω στην email_elem, περνάμε στο στοιχείο αυτό τη διεύθυνση του λογαριασμού μας. Αν πάμε στον Firefox, θα διαπιστώσουμε ότι έχει εμφανιστεί το όρισμα που δώσαμε στο αντίστοιχο πεδίο της φόρμας:
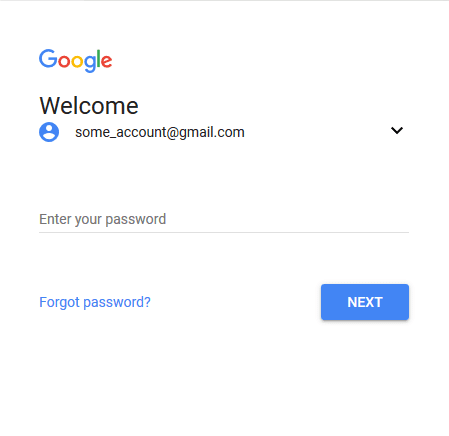
Έπειτα, με τη μέθοδο click() υλοποιούμε ένα προγραμματιστικό κλικ πάνω στο στοιχείο “identifierNext”, ώστε να μεταβούμε στην επόμενη σελίδα ελέγχου.
Εδώ θα επαναλάβουμε την παραπάνω διαδικασία, αυτή τη φορά για το στοιχείο με id “password”. Συμπληρώνουμε και εδώ με αυτόματο τρόπο τον κωδικό μας, και τον βλέπουμε να εμφανίζεται στη σελίδα του Gmail:
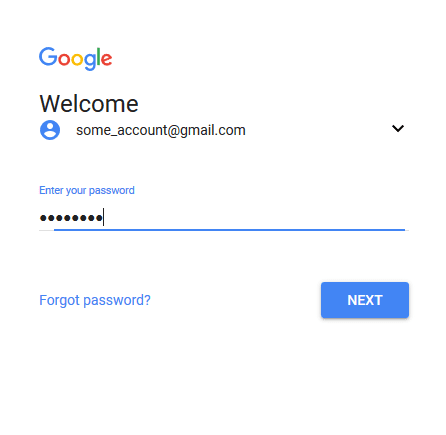
Τέλος, δεν έχουμε παρά να αναπαραστήσουμε ένα τελευταίο κλικ στο στοιχείο με id “identifierNext”. Προσέχουμε εδώ, ότι θα πρέπει να ξαναεντοπίσουμε το web element που μας πηγαίνει στην επόμενη σελίδα. Το γεγονός ότι πατάμε πάλι το “Next” δεν σημαίνει ότι πρόκειται για το ίδιο στοιχείο με πριν.
Στο επόμενο μάθημα για τον προγραμματισμό Python
Και την επόμενη εβδομάδα θα συνεχίσουμε με web scraping. Πριν δούμε το beatiful soup module, θα ρίξουμε μια ματιά στην HTML. Είδαμε κάποια στοιχεία σήμερα, αλλά αξίζει να αναφερθούν έστω τα (πολύ) βασικά, για να έχουμε μια ιδέα σχετικά με τη δομή μιας σελίδας στο ίντερνετ.
Σας άρεσε το σημερινό μάθημα για τον προγραμματισμό Python?
Ο χειρισμός browser και ιστοσελίδων είναι από τις πιο ενδιαφέρουσες εργασίες που μπορούμε να πραγματοποιήσουμε με τα προγράμματά μας. Δυσκολευτήκατε σε κάποιο σημείο ή σας γεννήθηκε οποιαδήποτε απορία? Γράψτε μας στα σχόλια.
Για να δείτε όλα τα μαθήματα Python από την αρχή τους, αλλά και τα επόμενα, αρκεί να κάνετε κλικ εδώ.




